
데이터셋 로딩
앞에서도 본것처럼 데이터셋 로딩하는 방법은 아래와 같습니다.
1. 기본 read함수로 로드하기
2. readr::read_delim()함수를 이용하여 로드하기
3. data.table::fread()함수를 이용하여 로드하기가 있습니다.
자세한 내용을 보고싶으면 여기를 참고하시면 됩니다.
데이터셋 로딩하기 - 플레인 텍스트 파일
데이터셋 로딩하기 먼저 아래와 같은 명령어를 통해 현재 작업 경로를 확인하고 변경하겠습니다. getwd() setwd('현재 작업하고 있는 경로') 저는 setwd에 제가 작업하는 주소가 /Users/hyeon-am/Desktop/Data
hyun-am-coding.tistory.com
데이터셋 탐색
간단탐색
먼저 간단한 탐색을 사용하는 head와 tail이 있습니다. 이 함수는 숫자를 지정해주지 않으면 앞에서 6개나 뒤에서 6개를 출력해줍니다.
만약 원하는 개수를 설정하고 싶으면 head(데이터,원하는 개수) 또는 tail(데이터, 원하는 개수)를 사용하면 됩니다.
예시 코드는 아래와 같습니다.
head(my)

tail(my)

만약에 head와 tail을 동시에 보고싶으면 psych라는 패키지에서 headTail을 이용하면 됩니다.
먼저 psych패키지를 설치하고 메모리에 로드하겠습니다.
install.packages('psych')
library(psych)이제 headTail을 사용하겠습니다. 구조는 다음과 같습니다.headTail(데이터, head길이, tail길이)
만약 아무것도 없이 headTail(데이터)를 사용하면
headTail(my)

head4개 tail4개가 출력된 것을 확인할 수 있습니다. 다음은 숫자를 지정해서 출력해보겠습니다.
headTail(my, 10, 5)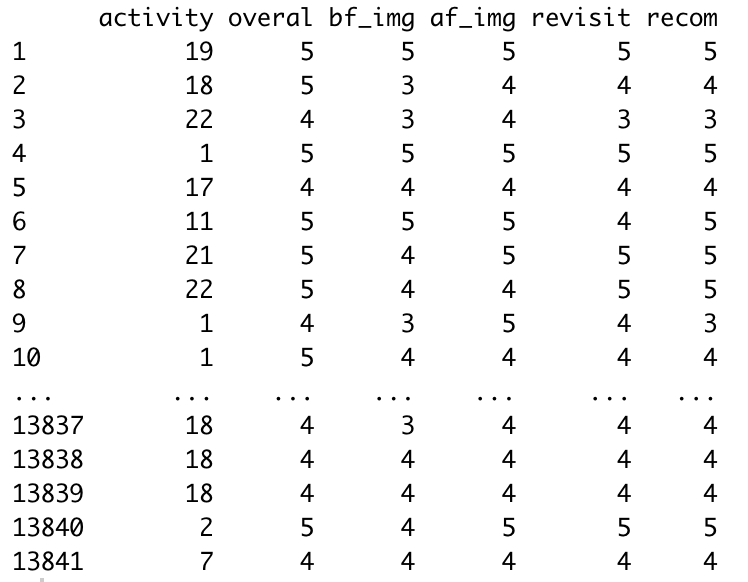
데이터셋 전체 내용 조회
데이터프레임객체로 로딩한 전체내용을 다양한 방식으로 조회할 수 있는데, 콘솔창에는 최대출력 옵션만큼의 데이터가 출력되며, 별도의 뷰어창에서는 정렬 및 간단 조회를 할 수 있습니다.
먼저 전체 내용 조회를 위한 print와 뷰어창으로 조회할 수 있는 View가 있습니다.
1. print로 출력했을 때

2. View로 출력했을 때
일반 엑셀에서 표를 보는것 처럼 출력이 되는것을 확인할 수 있습니다.

데이터셋 구조 파악하기
다음은 데이터셋 구조를 파악하기 위한 방법을 확인하겠습니다.
행과 열의 규모를 파악하는 dim( )
dim(my)
행의 이름을 파악해주는 rownames, row.names
rownames(my)
row.names(my)열의 이름을 파악해주는 colnames, names
colnames(my)
names(my)
데이터 내부구조 파악하기
먼저 앞에서도 경험해본 기본함수인 str을 이용해 구조를 파악하겠습니다.
str(my)
다음은 glimpse함수를 이용해 기본 구조를 파악해보겠습니다. 위에있는 기본함수인 str과는 비슷하면서도 다르게 생겼습니다.
만약 실행시키는데 패키지가 없다고 오류가 나오면 다음과 같은 패키지를 설치 및 로드를 해서 실행시켜줍니다.
intall.packages('dplyr')
library(dplyr)
glimpse(my)
데이터셋 요약하기
데이터셋 요약을 이용하면 중심성, 변동성, 정규성 측면에서 각 변수 컬럼별로 쉽게 파악할 수 있습니다.
먼저 기본함수인 summary를 사용해보겠습니다.
summary(my)
기술통계분석 패키지들
기술통계분석을 위해 psych, Hmisc, skimr패키지를 사용할건데 만약 설치되어 있지 않으면 설치한 후 진행하겠습니다. 만약 한꺼번에 설치하고 싶으면 다음과 같은 코드를 작성하겠습니다.
install.packages(c('psych', 'Hmisc', 'skimr'))1. psych::describe()를 이용한 기술통계분석
psych패키지에서 describe함수에서는 각 변수 컬럼별 여러가지 기술통계량을 세부적으로 비교해 줍니다.
psych::describe(my)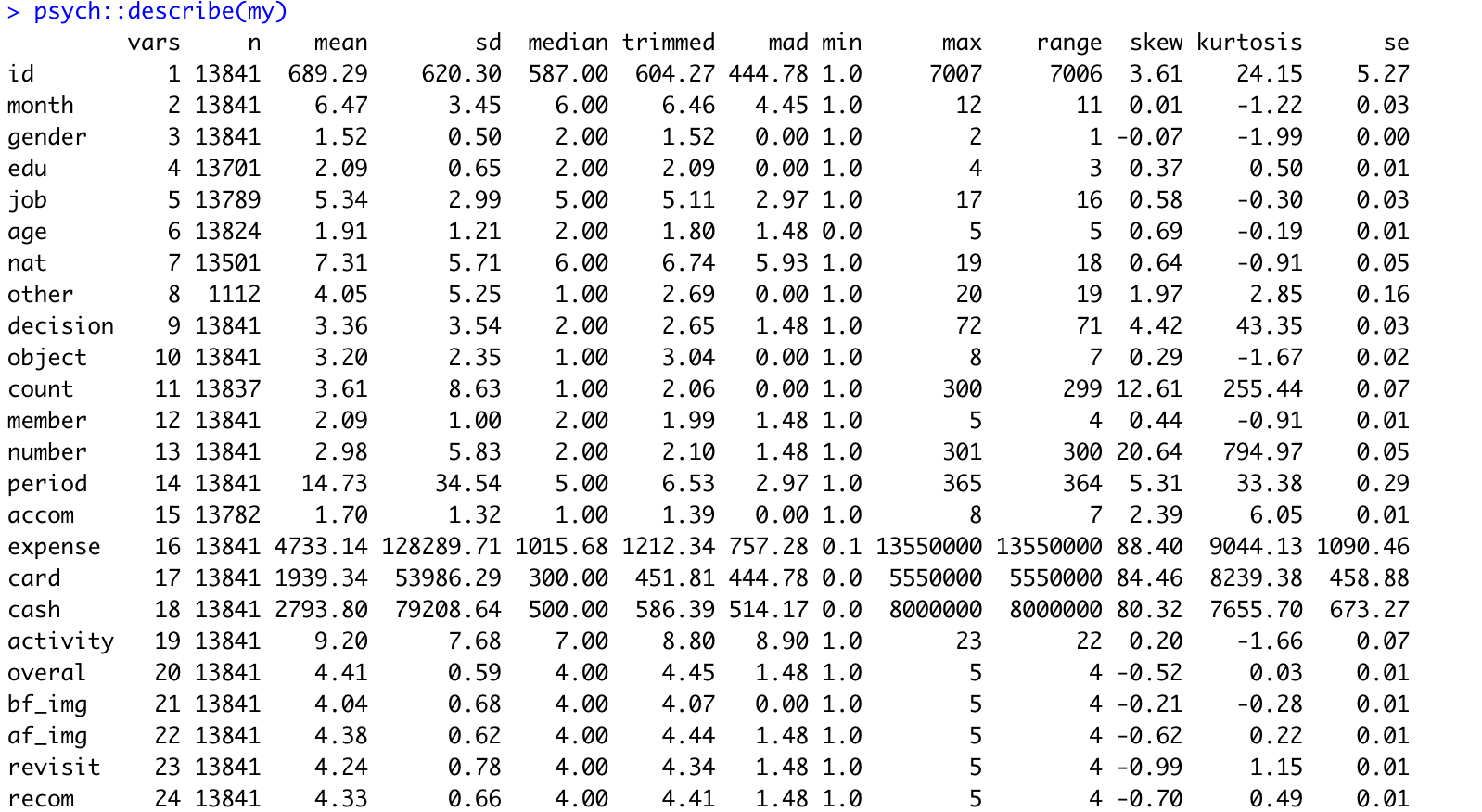
2. Himisc::descirbe()를 이용한 기술통계분석
Hmisc 패키지 describe()함수에서는 각 변수 컬럼별 단위로 기술통계량을 상세하게 제공합니다.
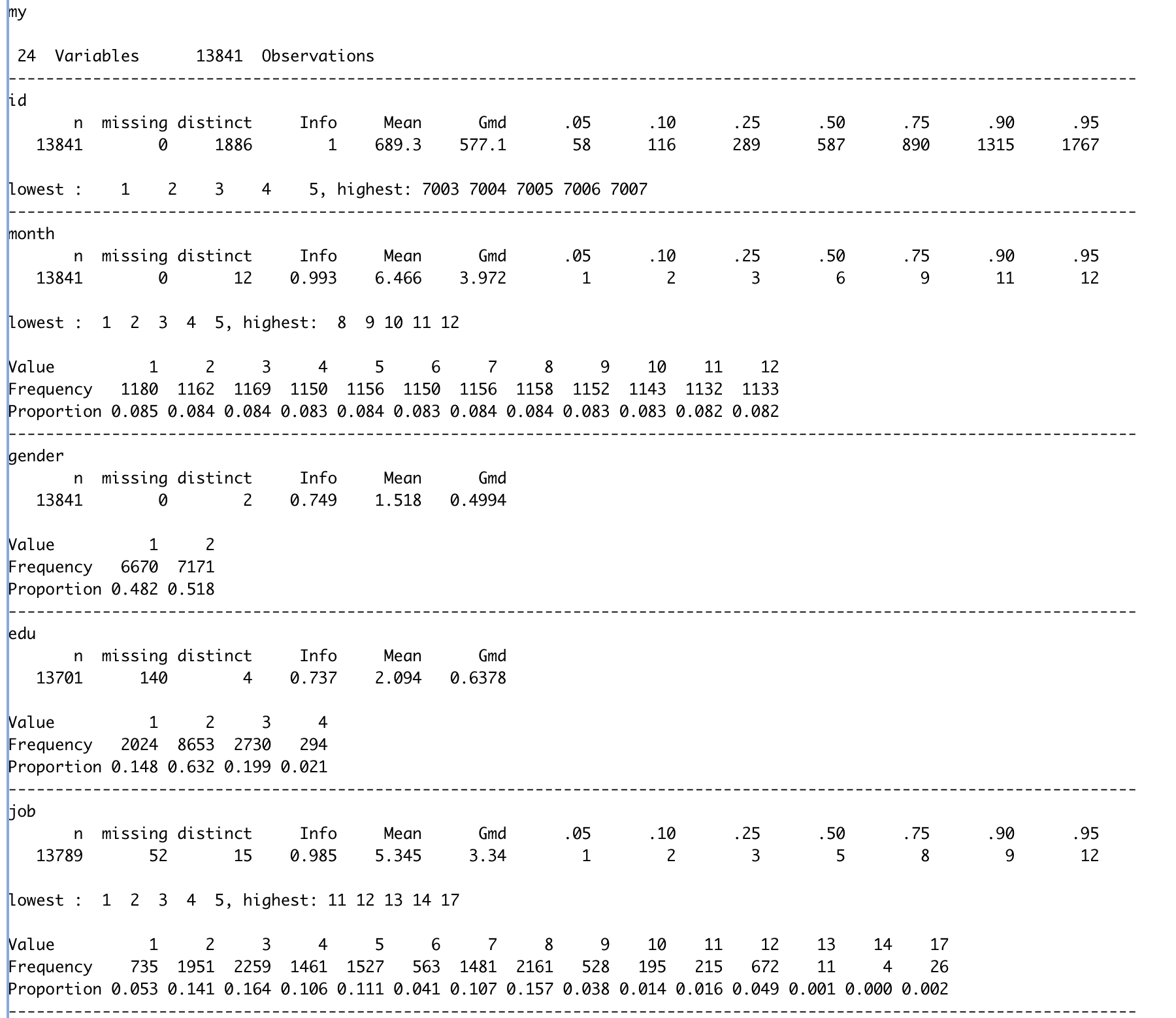

이런식으로 각 변수 컬럼별로 자세한 정보들이 나오는 것을 확인할 수 있습니다.
마지막으로 skimr에서 skim입니다.
3. simr::skim() 함수를 이용한 기술통계분석
skimr 패키지 skim함수에서는 각 변수를 측정척도별로 분리해 기술통계량과 히스토그램을 나타내줍니다.
skimr::skim(my)
히스토그램을 통해 데이터의 분포를 한눈에 알아볼 수 있습니다.
이 자료는 https://www.youtube.com/channel/UChPuesN49tcqQqYRQHrLCuw를 참조하여 작성하였습니다.
K-ICT 빅데이터센터
판교 K-ICT 빅데이터센터 공식 유튜브 채널입니다.
www.youtube.com
'Data·AI > R 데이터분석' 카테고리의 다른 글
| R. 범주형 변수 특성 요약과 시각화(이항형, 다향형) (0) | 2020.08.24 |
|---|---|
| R. 데이터 시각화탐색(산점도 매트릭스, 상관관계) (0) | 2020.08.24 |
| R. 데이터셋 로딩하기 - Excel, JSON, 외부링크 데이터 (1) | 2020.08.21 |
| R. 데이터셋 로딩하기 - 플레인 텍스트 파일 (0) | 2020.08.21 |
| R. 데이터셋 로딩하기 - 샘플데이터셋 (0) | 2020.08.21 |




댓글