
Elastic Search를 사용하기 전 기존 검색 기능에서 겪었던 사항들
- 정확도가 떨어진다(매우 중요)
- 기존에는 Django에서 Full Text Search를 위해 제공하는 SearchVector, SearchRank, SearchQuery를 이용해서 영어 검색에는 좀 정확할지라도 한글검색에서는 기존 사용자들이 익숙한 검색 결과를 받을 수 없습니다.
- 그렇게 많이 떨어지는건 아니지만 관련된 keyword들이 나오지 않는게 조금 문제였습니다. 예를 들면 스타벅스 아메리카노를 검색하면 정말로 스타벅스 아메리카노만 검색결과에 나오고 관련이 있는 스타벅스 또는 아메리카노는 결과에 안 나왔습니다.
- 비슷한 음식 검색이 가능한 타사 서비스가 있어서 유저들이 많이 비교한다.
- 느리다
- 항상 local서버와 QA서버에서 검색 기능을 사용했을때는 그렇게 까지 안느린데 OP환경에서는 매우 느립니다.
- 예상 되는 사항은 Full Text Search를 효율적으로 사용하기 위해 Gin Index를 사용했는데 이게 데이터베이스 에서 CPU를 많이 부하를 주는 작업이라 느려진거 같습니다.(예상, RDS 성능 개선 도우미를 통해 디비 상태를 보면 CPU가 엄청 많이 잡아먹은걸 확인 했습니다)
- 비효율 적으로 처리해서 빠르게 결과가 나와보이게 처리
- cache를 이용해서 해당 검색어에 대해 미리 저장을 해서 빠르게 검색 결과를 보여주도록 처리했습니다.
- 단점) 유저 custom음식 검색이 들어가기 전이라 그때까지는 효율적인데 만약 유저 custom음식이 추가되는 경우 해당 cache를 계속 refresh를 해줘야해서 비효율적
이제 유저들이 직접 음식을 추가할 수 있는기능을 추가해야 하기 때문에 Elastic Search를 도입하기로 결정했습니다.
Elasticsearch란
Elasticsearch는 강력하고 확장 가능한 분산 검색 및 분석 엔진입니다. 주로 로그 및 텍스트 기반 데이터의 실시간 검색, 분석, 시각화 등에 사용됩니다. Elasticsearch는 Apache Lucene 라이브러리를 기반으로 하며, 다양한 기능을 제공합니다.
elasticsearch에서 주요한 개념들
- 클러스터(Cluster) : Elasticsearch는 여러 개의 노드로 구성된 클러스터로 동작합니다. 클러스터는 동일한 클러스터 이름을 가진 모든 노드의 집합입니다. 또한 클러스터는 이름을 통해 구별이 가능합니다.
- 노드(Node) : 노드는 클러스터에 속한 단일 서버 인스턴스를 의미합니다. 각 노드는 데이터를 저장하고, 클러스트의 인덱스를 관리하고, 검색 작업을 수행합니다. 기본적으로 클러스터 하나에 노드 한개가 있지만 이것을 추가해서 클러스터를 확장 가능합니다.
- 인덱스(index) : 인덱스는 유사한 데이터의 집합입니다. 예를 들어, 특정 애플리케이션의 모든 사용자 데이터를 저장하는 인덱스를 만들 수 있습니다. 인덱스는 여러 개의 문서(Document)로 구성되며, 각 문서는 JSON 형식으로 저장됩니다.
- 유형(Type) : 이것은 논리적으로 문서를 그룹화하는 데 사용됩니다.
- 문서(Document) : 인덱스의 기본 단위로, JSON 형식으로 저장됩니다. 각 문서는 고유 식별자(ID)를 가집니다. 예를 들면 사요자 정보를 저장하는 문서에는 이름, 나이, 이메일 등의 필드가 포함될 수 있습니다.
- 샤드(Shard) : 샤드는 인덱스를 나누는 단위로, 데이터를 분산 저장하고 검색 성능을 높이기 위해 사용됩니다. 각 인덱스는 여러 개의 샤드로 구성될 수 있으며, 기본적으로 1차(primary) 샤드와 복제(replica) 샤드가 있습니다.
- 복제(Replica) : 1차 샤드의 복제본, 장애 발생 시 데이터 손실 방지 가능
elasticsearch의 주요 기능
- 실시간 검색 : 대용량 데이터를 빠르게 검색할 수 있게 도와줍니다. 쿼리를 통해 인덱스된 데이터에서 원하는 정보를 즉시 검색 가능하게 합니다.
- 분산형 구조 : 분산형 구조로 설계되어 있어, 데이터를 여러 노드에 분산 저장하고 처리할 수 있습니다. 확장성이 뛰어나며, 클러스터에 노드를 추가하여 쉽게 용량을 확장할 수 있습니다.
- RESTful API : RESTful API를 통해 데이터 CRUD(생성, 읽기, 업데이트, 삭제) 작업과 검색, 분석 작업을 수행할 수 있습니다.
- 고급 쿼리 언어 : Lucene(루씬) 쿼리 문법을 기반으로 한 강력한 쿼리 언어를 제공합니다.
Django에 Elasticsearch 결합하기
사용한 라이브러리
- elasticsearch==7.9.1
- elasticsearch-dsl==7.4.1
- django-elasticsearch-dsl-drf==0.22.5
elasticsearch은 8버전 이상도 있긴한데 저는 AWS에서 제공하는 OpenSearch에서 elasticsearch의 마지막 지원 버진이 7.x버전이기 때문에 7.x버전을 설치했습니다.
Docker를 통한 세팅
docker-compose.yml
volumes:
esdata1: {}
elasticsearch:
build:
context: .
dockerfile: ./compose/local/elastic_search/Dockerfile
container_name: elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata1:/usr/share/elasticsearch/data
ports:
- "9200:9200"
- "9300:9300"
kibana:
image: docker.elastic.co/kibana/kibana:7.16.3
container_name: kibana
environment:
ELASTICSEARCH_URL: http://elasticsearch:9200
ports:
- "5601:5601"
depends_on:
- elasticsearch
Dockerfile
FROM docker.elastic.co/elasticsearch/elasticsearch:7.16.3
RUN elasticsearch-plugin install <https://github.com/likejazz/seunjeon-elasticsearch-7/releases/download/7.16.3/analysis-seunjeon-7.16.3.zip>
→ 여기서 7.16.3 버전을 사용한 이유는 원래 nori tokenizer를 사용했더라면 굳이 버전 상관없이 잘 이용할텐데 AWS에서 elasticsearch를 이용하면 플러그인 설치를 못해서 elasticsearch에서 제공하는 은전한닢(analysis-seunjeon)을 이용하기위해 해당 버전을 이용했습니다.
→ 만약 그냥 aws이용없이 사용하거나 elastic 8버전이상을 사용하면서 nori tokenizer를 사용할거면 굳이 이런 세팅을 사용 안 하셔도됩니다. 또한 은전한닢 보다 nori tokenizer가 정확도는 더 좋은거같아요.
은전한닢이란?
Elasticsearch용 한국어 형태소 분석기 플러그인입니다. 이 플러그인은 한국어 텍스트의 분석을 돕기 위해 형태소 분석을 수행하여 보다 정확한 검색 결과를 제공합니다. 형태소 분석기는 텍스트를 더 작은 단위(형태소)로 분해하여 인덱싱 및 검색 성능을 향상시킵니다.
Django 기본 세팅하기
settings.py
INSTALLED_APPS=["django_elasticsearch_dsl","django_elasticsearch_dsl_drf"]
# elastic_search
ELASTICSEARCH_DSL = {
"default": {"hosts": "<http://elasticsearch:9200>"},
}
Document 추가하기
먼저 엘라스틱서치 document를 만들고 싶은 app에 들어가서 documents.py를 만들겠습니다.
documents.py
eunjeon_analyzer = analyzer(
"eunjeon_analyzer",
tokenizer="seunjeon_tokenizer",
)
@registry.register_document
class FoodInformationDocument(Document):
manufacturer = fields.ObjectField(properties={"name": fields.TextField()})
name = fields.KeywordField()
nickName = fields.TextField(analyzer=eunjeon_analyzer)
search_keyword = fields.TextField(analyzer=eunjeon_analyzer)
class Index:
name = "food_information"
settings = {
"number_of_shards": 1,
"number_of_replicas": 0,
"mapping": {"total_fields": {"limit": 5000}}, # 필요한 필드 수로 설정
"analysis": {
"analyzer": {
"nori_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer",
"filter": ["lowercase", "nori_part_of_speech", "cjk_bigram"],
"char_filter": ["html_strip"],
}
}
},
}
class Django:
model = FoodInformation
fields = [
"key",
"생략",
"createdAt",
"updatedAt",
]
def get_queryset(self):
return super().get_queryset().select_related("manufacturer")
def get_instances_from_related(self, related_instance):
if isinstance(related_instance, Manufacturer):
return related_instance.foodinformation_set.all()저는 django_elasticsearch_dsl에서 제공해주는 Document를 통해 기본 세팅을 했습니다. 해당 라이브러리를 이용하면 기존 Django model과 쉽게 결합을 해서 elasticsearch에 document생성을 도와줍니다.
기존에 제가 만든 코드와는 좀 다르지만 핵심이 되는 부분만 일단 가져왔습니다.
- manufacturer = fields.ObjectField(properties={"name": fields.TextField()})
- 음식정보에서 manufacturer 외래키로 사용되며 해당 manufacturer에서 name을 뽑아 document를 등록하기 위해 사용했습니다.
- 아래 나와있는 get_instances_from_related와 세트입니다.
- nickname과 search_keyword를 eunjeon_analyzer를 통해 분석할 수 있게 설정했습니다.
- nickname = f”{음식이름}({브랜드이름})” 이런 형태로 되어있습니다.
- search_keyword = f”{음식이름}({브랜드이름})”에서 공백이 제외된 상태로 되어있습니다.
- 여기서 name은 KeywordField로 설정했습니다. 그 이유는 정확한 이름정보 일치 검색에 유용해서 설정했습니다.
이런식으로 설정했다면 다음과 같은 명령어를 통해 elasticsearch에 index를 등록하겠습니다.
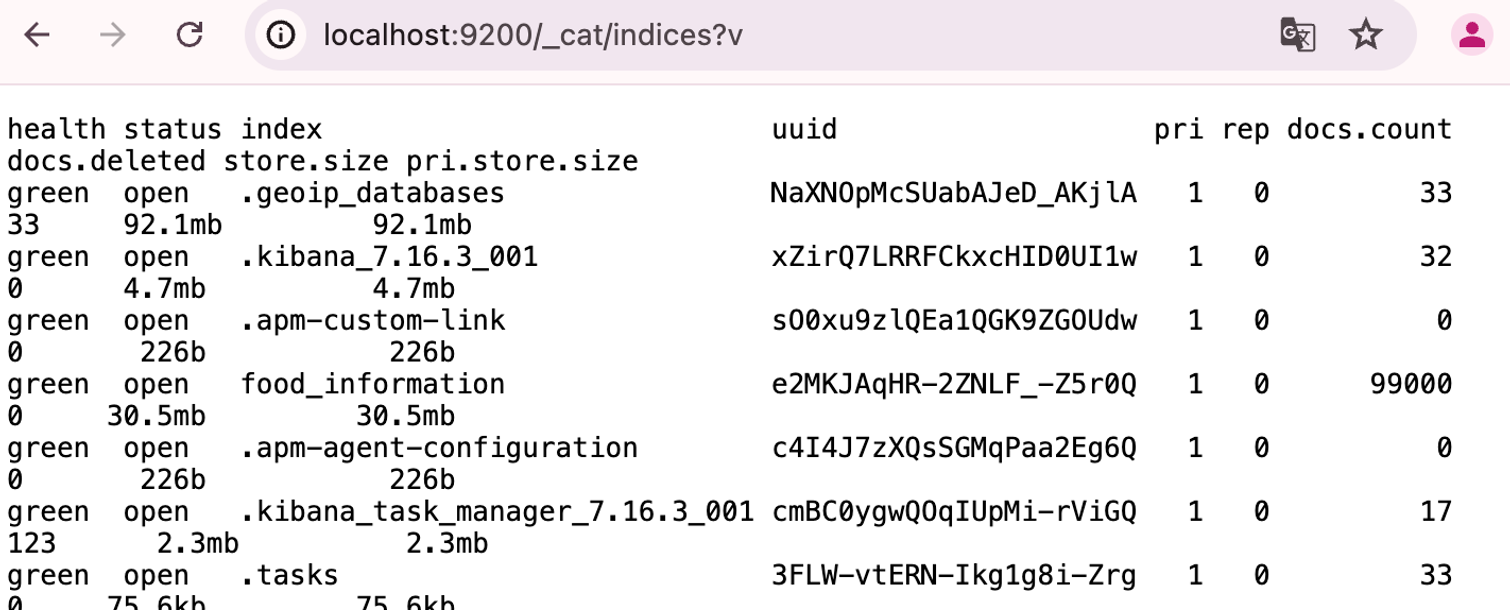
python manage.py search_index --rebuild다음과 같은 주소로 정보를 확인하면 food_information이라는 index가 잘 생성된 것을 확인할 수 있습니다.
생성한 document를 이용해 검색 구현하기
serializer 구현하기
- 제가 최대한 라이브러리를 이용해서 검색해보고싶어서 elasticsearch_dsl_drf에서 제공하는 DocumentSerializer를 통해 serializer를 구현했습니다.
- 이것을 통해 drf에서 serializer랑 비슷하게 데이터 직렬화가 가능합니다.
class FoodInformationDocumentSerializer(DocumentSerializer):
brand = serializers.SerializerMethodField("get_brand_name")
class Meta:
document = FoodInformationDocument
fields = (
"key",
"name",
"brand",
"nickName",
)
def get_brand_name(self, obj):
return obj.manufacturer.name if obj.manufacturer else NoneViewsetSet 구현하기
- 마찬가지로 DocumentViewSet이라는것도 제공해서 기존 drf에서 ModelViewSet코드 짜듯 작성했습니다.
class FoodInformationDocumentViewSet(DocumentViewSet):
document = FoodInformationDocument
serializer_class = FoodInformationDocumentSerializer
def get_queryset(self):
search_keyword = self.request.GET.get("keyword", "").strip()
include_custom = boolean_util(self.request.GET.get("includeCustom", True))
if not search_keyword:
return super().get_queryset()
# MultiMatch 쿼리 생성
multi_match_query = MultiMatch(
query=search_keyword,
fields=["name^3", "nickName^2", "search_keyword"],
type="most_fields",
fuzziness="AUTO",
)
# Function score 쿼리로 검색 점수 조정
function_score_query = FunctionScore(
query=multi_match_query,
functions=[
{
"filter":
Match(name={"query": search_keyword, "operator": "and"}),
"weight": 5,
},
{
"filter": Match(
nickName={"query": search_keyword, "operator": "and"}
),
"weight": 4,
},
{
"filter": Match(
search_keyword={"query": search_keyword, "operator": "and"}
),
"weight": 3,
},
{"filter": Term(name=search_keyword), "weight": 50},
{"filter": Term(nickName=search_keyword), "weight": 20},
{"filter": Term(search_keyword=search_keyword), "weight": 50},
],
score_mode="sum",
boost_mode="multiply",
)
# Elasticsearch 쿼리 수행
search = self.document.search().query(function_score_query)
if not include_custom:
bool_query = Bool(
must=[function_score_query], must_not=[Exists(field="user_id")]
)
search = self.document.search().query(bool_query)
return search
def list(self, request, *args, **kwargs):
user = request.user if not request.user.is_anonymous else None
self.request = request
queryset = self.get_queryset()
page = self.paginate_queryset(queryset)
if page is not None:
serializer = self.get_serializer(page, many=True)
results = serializer.data
# 점수 추가
for i, result in enumerate(results):
result["_score"] = page[i].meta.score
return self.get_paginated_response(results)
else:
serializer = self.get_serializer(
queryset,
many=True,
context={"user_id": user.key if user else None},
)
results = serializer.data
# 점수 추가
for i, result in enumerate(results):
result["_score"] = queryset[i].meta.score
return Response(results, status=status.HTTP_200_OK)라이브러리에서 제공하는 내용은 엄청 많은데 제가 사용한 부분에서 설명하겠습니다.
elasticsearch query
여기서 Pythonic한 개발을 위해 elasticsearch_dsl.query에서 제공하는 Bool, Exists, FunctionScore, Term을 사용했습니다.
from elasticsearch_dsl.query import Bool, Exists, FunctionScore, Match, MultiMatch, Term
- Bool : 여러 쿼리를 조합하는데 사용합니다. Bool은 must, should, must_not, filter와 같은절을 사용할 수 있으며 저는 유저 커스텀 음식을 포함하지 않을경우 포함해야하는 쿼리는 must에 넣고 제외할 항목들은 must_not에 넣었습니다.
- Exists : 특정 필드가 존재하는 문서를 검색하는데 사용합니다.
- 예시 → Exists(field="user_id") : user_id 필드가 존재하는 문서 검색
- FunctionScore : score(가중치, 함수)등을 조정할때 사용합니다.
- Match : 텍스트 기반 필드의 값과 일치하는 문서를 검색하는 데 사용됩니다. 분석기가 적용되어 토큰화된 값을 비교합니다.
- MultiMatch : 여러 필드에서 텍스트 기반 값을 검색하는데 사용합니다.
- Term : 완전 일치 검색을하는데 도움을 줍니다.
그 외에 설명이 필요한 사항
MultiMatch에 다음과 같은 항목이 있는데 여기서 ^n 은 가중치를 얼마나 줄 지 설정이 가능합니다.
fields=["name^3", "nickName^2", "search_keyword"]
fuzziness는 입력한 항목에서 단어 유사 검색을 해줍니다.
fuzziness="AUTO",
참고한 문서
- elasticsearch_dsl : https://elasticsearch-dsl.readthedocs.io/en/latest/index.html
- elasticsearch_dsl_drf : https://django-elasticsearch-dsl-drf.readthedocs.io/en/latest/
- elasticsearch : https://www.elastic.co/docs
- 형태소 분석 : https://esbook.kimjmin.net/06-text-analysis/6.7-stemming/6.7.2-nori
- 엘라스틱서치 한글 가이드 : https://esbook.kimjmin.net/
Elastic 가이드 북 | Elastic 가이드북
이 가이드북은 출판을 위해 집필중이던 내용을 Elastic을 처음 시작하시는 분들께 도움이 되고 커뮤니티와 함께 완성 해 나가려는 목적으로 공개하게 되었습니다. 모든 문서에 대한 저작권은 저
esbook.kimjmin.net
6.7.2 노리 (nori) 한글 형태소 분석기 | Elastic 가이드북
이 문서의 허가되지 않은 무단 복제나 배포 및 출판을 금지합니다. 본 문서의 내용 및 도표 등을 인용하고자 하는 경우 출처를 명시하고 김종민(kimjmin@gmail.com)에게 사용 내용을 알려주시기 바랍
esbook.kimjmin.net
Documentation
Elastic documentation
www.elastic.co
'Django > Django REST framework' 카테고리의 다른 글
| Django 코드 품질 향상시키기(with black, isort, flake8, pre-commit, makefile) (0) | 2024.04.22 |
|---|---|
| DRF throttling 사용기 (0) | 2023.01.08 |
| 15. Throttling (0) | 2022.08.25 |
| Sendbird를 이용한 DRF 채팅서버 구현 (0) | 2022.06.24 |
| Django FCM 개발(DRF) (0) | 2022.03.01 |




댓글