
비율형 척도 변수컬럼 특성 파악하기
비율형 척도 (ratio) 중에서 지출경비(expense)변수를 선정하여 지출경비 수치들이 가진 중심성, 변동성, 정규성 분포 특성을 파악합니다.
먼저 expense 컬럼을 뽑아내서 어떤 데이터인지 파악하겠습니다.
library(Hmisc)
Hmisc::describe(cnt$expense)
이제 산술평균, 중앙값, 최빈값을 파악하겠습니다.
1. 산술평균
mean(cnt$expense)
mean(cnt$expense, na.rm = TRUE)
mean(cnt$expense, na.rm = TRUE, trim = 0.3)
여기서 trim = 0.3을 적용한 mean을 보면 다른 값들에 비해서 현저히 낮은 것을 확인할 수가 있습니다. 이것은 평균에 비해서 극값이 있다는 사실을 파악할 수 있습니다.
2. 중앙값 확인하기
median(cnt$expense)값은 1015.68이 출력됩니다.
3. 최빈값 출력하기
먼저 최빈값을 구하기 위해 expense컬럼으로 된 값을 테이블로 볼 수 있는 변수로 만들겠습니다.
expense_freq <- table(cnt$expense)
expense_freq그러면 다음과 같이 값들이 오름 차순으로 된 것을 확인할 수 있습니다.

이제 sort함수를 통해 이것을 내림차순으로 변경하겠습니다.
sort(expense_freq, decreasing = TRUE)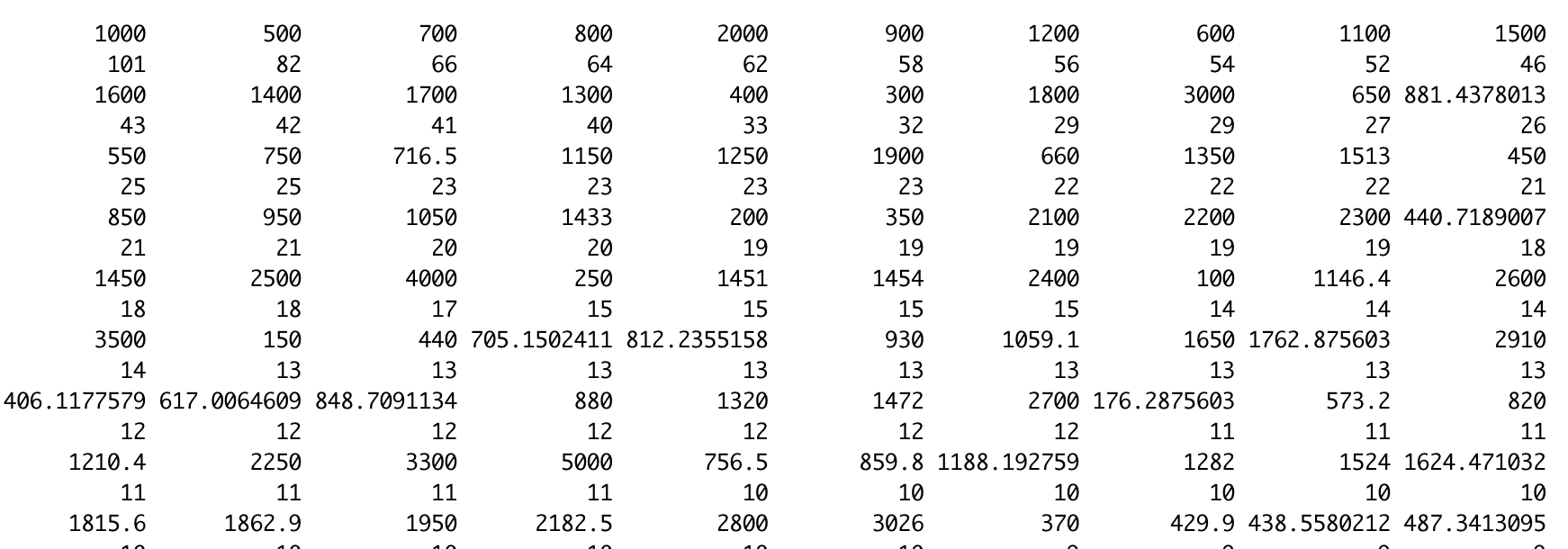
그러면 이런식으로 내림차순으로 변경된 것을 확인할 수 있습니다. 그러면 어떤 값이 최빈값인지 확인할 수 있습니다.
아니면 which.max함수를 통해 어느값이 최빈값인지 확인할 수 있습니다.
names(which.max(expense_freq))값은 1000이 나오는 것을 확인할 수 있습니다.
4. 분산, 표준편차, 범위, (최대,최소) 확인하기
분산
var(cnt$expense)
var(cnt$expense, na.rm = TRUE)
분산 값이 엄청 크게 나타난 것을 확인할 수 있습니다. 이말은 데이터가 엄청 다양하게 분포되어 있음을 확인할 수 있습니다.
표준편차
sd(cnt$expense)
sd(cnt$expense, na.rm = TRUE)
마찬가지로 표준편차 값이 크므로 데이터가 다양하게 분포되어 있음을 확인할 수 있습니다.
범위
range(cnt$expense)
range(cnt$expense, na.rm = TRUE)
최대/최소
max(cnt$expense)
min(cnt$expense)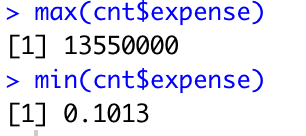
5. 왜도와 첨도
왜도
skewness(cnt$expense)
skewness(cnt$expense, na.rm = TRUE)
값들이 양수로 되어 있으므로 중앙값을 기준으로 좌측으로 밀집됨을 확인할 수 있습니다.
첨도
kurtosis(cnt$expense)
kurtosis(cnt$expense, na.rm = TRUE)
첨도값이 큰값으로 되어 있으므로 중앙 값으로 엄청 뾰족할수도 있다는 것을 예상할 수 있습니다.
이제 시각화를 통해 예상한 것들이 맞는지 확인하겠습니다.
⭐️ 비율형 척도 변수컬럼 시각화하기
먼저 간단한 플로팅 후 가이드 라인과 같이 표현하겠습니다.
plot(cnt$expense, type = "p",
pch = 21, bg = "green")
# abline()을 이용한 가이드라인(안내선)을 그리기
abline(h = seq(from = 1,
to = 13000000,
by = 1000000),
col = "gray", lty = 2)
abline(v = seq(from = 1000,
to = 14000,
by = 1000),
col = "gray", lty = 2)
값이 다음과 같이 나온것을 확인할 수 있습니다.
다음은 히스토그램을 그려서 파악해보겠습니다.
par(mfrow=c(2, 2))
hist(cnt$expense, main="hist(), Frequency 옵션")
hist(cnt$expense, probability=TRUE,
main="hist(), Probabilty 옵션")
plot(density(cnt$expense), main="density() 확률밀도 옵션")
hist(cnt$expense, probability=TRUE,
main="hist() 히스토그램과 density() 확률밀도함수 통합")
lines(density(cnt$expense))

이 자료는 https://www.youtube.com/channel/UChPuesN49tcqQqYRQHrLCuw를 참조하여 작성하였습니다.
K-ICT 빅데이터센터
판교 K-ICT 빅데이터센터 공식 유튜브 채널입니다.
www.youtube.com
'Data·AI > R 데이터분석' 카테고리의 다른 글
| R. 범주형 변수간 특성요약과 시각화 (1) | 2020.09.02 |
|---|---|
| R. 연속형 변수 특성 요약과 시각화(등간형) (0) | 2020.08.24 |
| R. 범주형 변수 특성 요약과 시각화(이항형, 다향형) (0) | 2020.08.24 |
| R. 데이터 시각화탐색(산점도 매트릭스, 상관관계) (0) | 2020.08.24 |
| R. 데이터 탐색하기 (0) | 2020.08.21 |




댓글